Development
and Validation of the Objective Scoring System, version 3
by
Raymond Nelson, Mark Handler, and Donald Krapohl
**
NEW ** Lafayette Instrument's OSS-3 Report
Home
Poster
#1 - Development and validation
Poster
#2 - Validation with mixed format field investigation
polygraphs
Poster
#3 - Additional validation with LEPET and PCSOT screening
exams
The OSS-3
Report
Other
Materials
Introduction
The OSS 1 and 2 methods were limited to only single-issue ZCT formats with three relevant and three comparison questions. It was not designed for other question configurations, nor for multiple-issue and multiple-facet testing, approaches that account for a significant portion of all testing conducted in the field. Here we discuss the development of a third generation of OSS to overcome these limitations. The objectives were to:
* Re-develop the OSS to accommodate a wider variety of polygraph techniques;
* Develop a data model to take advantage of additional test charts;
* Design a data structure and evaluation method that is more robust against artifacted, missing or uninterpretable data;
* Provide a method that can accommodate mixed-issue screening examinations, and;
* Provide a well documented and openly published polygraph scoring method based upon easily recognized theoretical and statistical principles and existing research in polygraph scoring and decision rules.
Method
In the development of OSS-3 we used three primary Kircher features and ratios (see Krapohl & McManus, 1999, for details). We began by taking the natural logarithm of the asymmetrical ratios, standardize them for each component using the mean and standard deviation values obtained through a bootstrap of 10,000 resampled sets of size equivalent to the training dataset of confirmed ZCT cases (N=292) from the sample for OSS versions 1 and 2. We combined the standardized component values within each test chart of the training dataset using a weighted mean procedure that emphasized the component contributions: electrodermal activity = .5, cardiograph = .33, and pneumograph = .17. These differed slightly from the component weights of OSS-1 and 2.
We then combined the weighted means from the three to five test charts, using the mathematical mean for each of the relevant questions and a grand mean of all relevant questions. By averaging the data in this manner we were prepared to evaluate each of the relevant questions as a distinct value as in the case of multi-facet and mixed issues exams, and were also prepared to further average the relevant questions together for a single value representative of each test as a single-issue investigation.
We completed a second bootstrap resample of the combined data from our training dataset, to construct two cumulative distribution functions which were used to determine the proportion of truthful and deceptive persons who would produce a greater or lesser score than that observed in a single individual. The cumulative distribution function for a single examination, when compared with a specified alpha threshold, became our measurement of significance, following the procedure first suggested by Barland (1985). Because OSS now provides point estimates for both overall and question-by-question results, we were able to incorporate improved two-stage decision rules into the algorithm, after the findings of Senter and Dollins (2003) and Senter (2003), alongside the single-stage decision model of earlier OSS versions. We investigated the ability of two stage rules seek to 1) improve sensitivity to deception while 2) maintaining optimal test specificity.
Training Sample
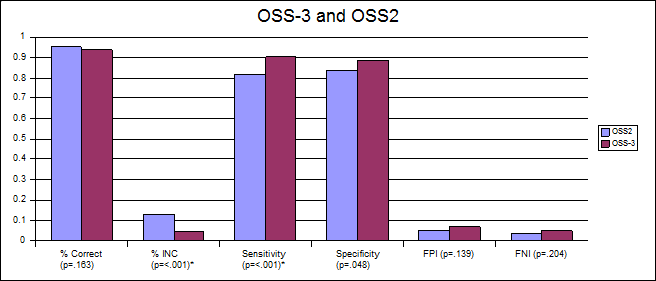
Using double-bootstrap mean and standard-deviation estimates, we used a Bonferonni corrected t-test to investigate the significance of observed differences in the results of the OSS-3 and OSS-2 methods along several axes, including; percent correct, inconclusive rates, sensitivity to deception, specificity to truthfulness, false positive rates, and false negative rates. We found that the OSS-3 method, using two-stage decision rules (Senter Rules), provided a significant improvement over OSS-2. See Table 1 and Chart 1.
Table 1. Comparison of performance for OSS-3 and OSS-2 with training data.
OSS-3/Senter
OSS-2
sig.
Correct Decisions 93.9% 95.3% .163
INC 4.4% 12.9% <.001*
Sensitivity 90.6% 81.9% <.001*
Specificity 88.8% 84.0% .048†
FN 6.6% 4.7% .139
FP 4.8% 3.5% .204
* denotes statistically
significant improvement of OSS-3 over OSS-2.
†
Not
Significant. Using a Bonferonni correction, significance at .05 would
require an
observed significance level
<=.008.
Chart 1.
OSS-3 and OSS-2.
Validation Sample
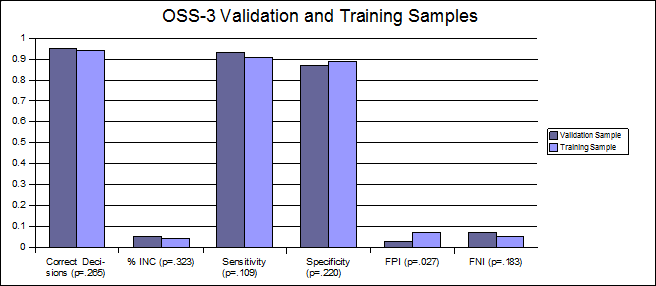
We constructed another double-bootstrap Bonferonni t-test to investigate the significance of observed differences in the results of the OSS-3/Senter method with the training sample and a validation sample of 60 confirmed ZCT examinations which was selected at the same time as the OSS training sample, and was used as the validation sample for OSS versions 1 and 2. This double bootstrap differs from that of the original validation experiment only in that our validation sample is not equivalent in size to the training dataset. For that reason we used M=2922 resample sets for our training sample and M=602 resample sets for our validation sample. Results from this experiment revealed no significant differences between the outcomes of the OSS-3/Senter method between the training and validation samples. This suggests no decrement in performance when using the OSS-3 algorithm on the validation set. See Table 2 and Chart 2.
Table 2. Comparison of performance for OSS-3 with validation and training samples.
Senter Rules
(two-stage)
Validation Sample
Training Sample
(N=60)
(N=292)
sig.
Correct Decisions 94.7% 93.9% .265
INC 5.0% 4.4% .323
Sensitivity 93.3% 90.6% .109
Specificity 86.7% 88.8% .220
FN 3.3% 6.7% .027†
FP 6.7% 4.9% .183
† Not Significant. Using a
Bonferonni correction, significance at .05 would require an
observed
significance level
<=.008.
Chart 2. OSS-3
Validation and Training Samples.
Discussion
The OSS-3 method appears capable of performing as well or better than previous OSS versions using the training sample, and data indicate the method can be generalized to other datasets. The data structure and mathematical transformations of the OSS-3 method can theoretically generalize to the variety of recognized Zone and MGQT examination techniques employing two to four relevant questions, and can exploit the advantages of three to five test charts, as described by Senter, Dollins, and Krapohl (2004), and Senter and Dollins (2004). Equally important, the OSS-3 framework can be theoretically applied to single-issue, multi-facet, and mixed-issues testing objectives if decision rules are designed to accommodate the differences.
Next we will investigate the effectiveness of the OSS-3 method with mixed format cases, including multiple variants of the Zone and MGQT techniques with two to four questions. Following that we will investigate the efficacy of OSS-3 with screening examinations using LEPET and PCSOT field samples.
References
Barland G.H. (1985). A method for estimating the accuracy of individual control question tests. Proceedings of Identa-85, 142-147.
Krapohl, D.J., and McManus, B. (1999). An objective method for manually scoring polygraph data. Polygraph, 28(3), 209-222.
Senter, S.M. (2003) Modified general question test decision rule exploration. Polygraph, 32(4), 251-263.
Senter, S. M., Dollins, A. B., and Krapohl, D. J. (2004). A comparison of polygraph data evaluation conventions used at the University of Utah and the Department of Defense Polygraph Institute. Polygraph, 33(4), 214-222.
Senter S.M., and Dollins. A.B. (2003). New decision rule development: Exploration of a two-stage approach. (DoDPI01-P-0006). Fort Jackson, SC: Department of Defense Polygraph Institute.
Senter S.M., and Dollins. A.B. (2004). Comparison of question series and decision rule: A replication. Polygraph, 33(4), 223-233.