Cross
Validation of the Objective Scoring System, version 3
by
Raymond Nelson, Mark Handler, and Donald Krapohl
**
NEW ** Lafayette Instrument's OSS-3 Report
Home
Poster
#1 - Development and validation
Poster
#2 - Validation with mixed format field investigation
polygraphs
Poster
#3 - Additional validation with LEPET and PCSOT screening
exams
The OSS-3
Report
Other
Materials
Introduction
We investigated the validity of the Objective Scoring System, version 3 (OSS-3) with a sample of mixed format cased from the Defense Academy of Credibility Assessment (DACA) confirmed case archive. Having satisfied our initial objectives to untether the Objective Scoring System (OSS) (Dutton, 2000; Krapohl, 1999; Krapohl, 2002; Krapohl & McManus, 1999) from the theoretical and practical constraints imposed by the previous cumulative data structure, we were satisfied that OSS-3 performed as well or better as previous versions, with the initial training and validation samples. Equally important, the new method can be theoretically generalized to polygraph techniques other than the venerable three-question, three-chart single-issue Zone Comparison Technique (ZCT or Zone) technique. The range of techniques available includes variants of the Zone format, along with variants of the Modified General Question Technique (MGQT).
In this study, our objectives were to:
* Investigate the validity of the OSS-3 method with a cross validation sample of confirmed field investigation cases, constructed from mixed-format examinations drawn from the DACA confirmed case archive;
* Evaluate the accuracy of the OSS-3 algorithm with techniques with varying numbers of relevant questions, and;
* Investigate the efficacy of different decision rules (Spot score and Senter Rules).
Not addressed is the use of the OSS-3 method with mixed-issue screening examinations or DLC technique. Examinations of those types are not included in the cross validation sample.
Cross validation sample
We selected a matched sample
of 70 examinations, 35 confirmed truthful and 35 confirmed deceptive,
from the DACA confirmed case archive. The selection criteria
were: the ground truth status of each selected case; criminal suspect
cases only; and the examinations must include artifact-free or
interpretable presentations of at least two relevant questions, and
at least three charts. Table 1 lists the type of examination
techniques in the cross validation sample. Of the 70 cases, 67 had
three charts and 3 cases had four charts.
Table 1. Examination
Techniques
ZCT
28
You-Phase
5
Army MGQT
23
USAF
MGQT 12
Navy MGQT
1
USSS MGQT
1
Total
70
Decision Rules
In addition to the Grand Mean decisions rules we evaluated OSS-3 decision rules that are analogous to the spot scoring rules familiar to field examiners. While the ZCT and its variants are thought of as single-issue examinations, a substantial portion of field examinations employ multiple-facet strategies. Multiple-facet examinations differ from single-issue examinations in that in the former it remains conceivable that an examinee could lie to one or more test questions while being truthful to others, though they all relate to the same crime. However, we do not propose that our mathematical transformations of the OSS-3 method will be able to determine deception or truthfulness simultaneously. Instead polygraph decision rules will be implemented sequentially and independently. Underlying mathematical transformations for our Spot Rules were identical to those employed with the Senter rules (Senter, 2003; Senter, Dollins, 2003, 2004; Senter, Dollins & Krapohl, 2004) and grand mean decision rules.
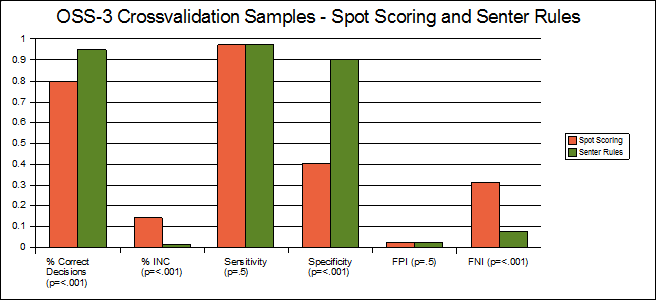
Similar to our previous experiments, we used double bootstrap resampling to investigate differences in performance outcomes using the OSS-3/Spot and OSS-3/Senter decision rules. Our double bootstrap consisted of M=702 resample sets from our cross validation sample (N=70), from which we were able to take the means of both observed decision accuracy rates and the standard deviations of the accuracy rates in our observed sample sets, to use as population estimates for a Bonferonni t-test. Differences in decision accuracy between the spot-scoring rules and Senter rules was significant (p=<.001) with the spot scoring rules producing 79.9% correct decisions compared with 94.8% for the Senter rules. See Table 2 and Chart 1.
Table 2. Crossvalidation data
Spot
Scoring
Senter Rules
sig.
Correct Decisions 79.9% 94.8% <0.001
INC 14.3% 1.2% <0.001
Sensitivity 97.5% 97.5% .500†
Specificity 40.3% 90.1% <0.001
FN 2.5% 2.5% .500†
FP 31.5% 7.5% <0.001
† Not
Significant.
Chart 2. Crossvalidation Data.
We conducted another Bonferonni t-test to evaluate the difference in performance outcomes of the OSS-3/Senter method using another double bootstrap Bonferonni t-test with N=2922 confirmed ZCT cases from the training sample, and M=702 resample sets from the crossvalidation sample. Results from that experiment revealed no significant differences between the performance of the OSS-3/Senter algorithm with the ZCT cases in the training sample and the mixed format cases in the crossvalidation sample. See Table 3 and Chart 2.
Table 3. Training and crossvalidation data.
Using Senter
Rules
Crossvalidation Sample Training
Sample
sig.
(M=702)
(M=2922)
Correct Decisions 94.1% 93.9% .473
INC 2.8% 4.4% .158
Sensitivity 94.3% 90.7% .128
Specificity 88.7% 88.8% .495
FN 3.2.% 6.6% .094
FP
4.4%
4.5%
.492
Chart 2. Crossvalidation and Training Data.

Discussion
Based on the cross validation results, the Senter Rules performed significantly better than Spot Scoring. Spot scoring rules resulted in a substantially higher inconclusive and false positive rates, and is consistent with mathematical expectations based on the addition rule for dependent probability events. Therefore, we decided to forgo further interest in Spot scoring rules as they apply to the mixed-format cases. Because the OSS-3/Senter algorithm provide a more robust classification efficiency with the mixed format cases, we decided to employ it with all polygraph techniques, including all variants of the Zone and MGQT methods.
Despite our favorable observations, we remain aware that we have still not evaluated the OSS-3 algorithm with mixed issue/screening examinations, which are distinct from both single-issue and multi-facet exams, and impose additional complications from the use of distinct and logically independent question targets, such as when a test subject could be truthful to questions about involvement in one target concern while lying about his or her involvement in another investigation target.
In our next experiments, we will investigate the usefulness of OSS-3 method with screening examinations including LEPET, and PCSOT sample data.
References
Dutton D.W. (2000). Guide for performing the objective scoring system. Polygraph, 29(2), 177-184.
Krapohl, D.J. (1999). Short report: Proposed method for scoring electrodermal responses. Polygraph, 28(1), 82-84.
Krapohl, D.J. (2002). Short report: Update for the objective scoring system. Polygraph, 31(4), 298-302.
Krapohl, D.J., & McManus, B. (1999). An objective method for manually scoring polygraph data. Polygraph, 28(3), 209-222.
Senter (2003) Modified general question test decision rule exploration. Polygraph, 32(4), 251-263.
Senter, S. M., Dollins, A. B., & Krapohl, D. J. (2004). A comparison of polygraph data evaluation conventions used at the University of Utah and the Department of Defense Polygraph Institute. Polygraph, 33(4), 214-222.
Senter S.M., & Dollins. A.B. (2003). New decision rule development: Exploration of a two-stage approach. (DoDPI01-P-0006). Fort Jackson, SC: Department of Defense Polygraph Institute.
Senter S.M., & Dollins. A.B. (2004). Comparison of question series and decision rule: A replication. Polygraph, 33(4), 223-233.